亚太数模总结
前期准备
-
组队
不论是什么比赛,团队是我认为最重要的key factor。对于一项我比较重视的比赛,我往往会选择作为队长参加,因为我想自己选择我最信任的朋友来组队和奋斗。
这里插一句题外话,我真的很感激一路上的合作伙伴们:写书的时候的李帕、冰糖、zang、juns、kouzong;服创时候的谌总、cyy、ruia、佳宁姐,后期加盟的林导林铁蛋;互联网+的时候被强势带飞的Jacob学长;亚太数模的cherish和ruia…感谢队友们对我的信任,也感谢很多人一路上不离不弃。
说回亚太,一般来说,数模比赛的队友会是这么一个配置模式:
建模手(编程手亦可) * 1
数学手(个人理解是出solution的人) * 1
英语 * 1
当时我组队的时候也没想太多,比起按照配置对号入座,我认为还是能把话说到一块去的人更合适,于是找了熟悉且靠谱的朋友开干。其实整体做下来,感觉这个配置模式是可以灵活替换的,也并不是一个基准(当然,也很可能是因为我们都是第一次参加,比较混乱)。实际上我们队伍的实际情况是:
Day 1:我和cherish是数学手思考solution,ruia做数据的收集
Day 2:我和cherish是编程手,通宵把solution付诸实践,ruia变成论文手兼数据收集
Day 3:ruia变成数学手,针对solution做modify,cherish继续编程建模,我变成论文手写摘要
Day 4:ruia提出一个很有趣的解决方案,我又变成编程手实现,cherish写论文。
所以实际上呢,职责是跳脱的,也是混乱的。从一个新手的角度出发,我还是鼓励大家从综合实力强合得来的朋友组队,第一次很难做到职责分明,所以需要大家都能时刻统一意见然后具有多面的解决问题的能力,及时帮忙救火。
-
前一个月
没错,我们提前一个月就开始有一些规划。大抵是一个月或者是三个星期吧,记不太清楚。这是我当时认为很重要的事情,因为我们都是没有参加过数模比赛的小白,**所以我认为需要对基础的一些模型进行涉猎和了解,对一些数学概念做基本的学习。**于是当时我统计了一些很常见的在数模比赛中比较基础的方法,然后每个人分门别类地安排去学习,每周汇报一次(类似组会),把这个模型有关的知识记录下来,大家都能看到。

上图是第一次开会后分配的任务。
下面截取一部分我们每周的一些总结:



当然,事实上比赛最后绝大部分的算法没有用到,但是毕竟我们的目的是学习嘛,学到了就不亏,何况还拿了奖。
现在回过头来看看,大家还是很努力的,棒!
比赛开始
-
Timeline
先说一下时间线。
gantt dateFormat YYYY-MM-DD title 亚太时间管理甘特图 section 我 理解问题 :done, des1, 2021-11-25,12h 思考解决方案 :active, des2, 2021-11-25,2d 编程建模 : crit, done, des3, after des1, 2d 论文写作 :active, after des2,2d section ruia 理解问题 :crit, done, 2021-11-25,12h 查找相应数据与文献 :crit, done, 2021-11-25,2d 论文准备工作 :crit, done, 2021-11-26,36h 完善解决方案 :crit, 2021-11-27,24h 论文写作 :active, after des2,2d section cherish 理解问题 :crit, done, des4,2021-11-25,12h 思考解决方案 :active, des1, 2021-11-25,1d 数据集处理 :done,after des4,36h 编程建模 : crit,done , des3, after des1, 2d 论文写作 :active, after des2,2d借用一下甘特图,使用不是很严谨,不过大体流程八九不离十。我把“完善解决方案”标红了,因为这个部分我认为是当时比较关键的一件事情,把四个问题的解决方案串了起来。
总体上,最耗时的工作是:**数据搜集、编程、写作。**而且比赛第一天正好我是满课,基本上没有做特别多的工作。主要的部分都是第二天通宵和周六周日做完的。接下来,我也会围绕这几个耗时最长的部分谈谈感受。
-
数据搜集
由于我们选了技术含量相对最低的C题,分析塞罕坝的环境影响并且对研究结果做迁移,我们需要搜集特别多的数据来进行分析。
一些传送门:
…
很多网站也记不清了,大体上就是广撒网式搜刮数据。北京市的沙尘天气数据甚至是在一篇报告中获得的,总的来说就是,各种搜索引擎一起使用,有必要的话可以借助爬虫。
数据搜集起码占了我们前两天75%的时间,没有数据,无从开始。
这里也有一点个人建议:数据总是很零碎的,尤其是环境题,不要强求从解决方案的角度搜集所需要的数据,而是要从搜索到的数据上建立解决方案。
-
编程建模
获取一定数量的数据后,就是建模环节。因为我们这次第一第二题的方向是做分析,所以基本上是一些分析方法的使用。
很多人说,层次分析法、灰度预测等等,都是很简单老套的模型,没有任何竞争力,但其实它们也有存在的意义。刚拿到手的数据,可以用简单的方法跑一下看看结果是否和自己猜测的接近,做一个初步的判定之后也能为解决方案确定方向。这里大概说一下我们要解决的问题以及最后我们的整体设计:
问题:
Q1:根据各种环境因子建立塞罕坝环境评估模型,对比分析塞罕坝治理前与治理后对周边环境的影响。
Q2:评估塞罕坝治理对北京抗风沙能力的影响,量化评估塞罕坝在其中的作用。
Q3:对塞罕坝的治理模式做迁移,找到国内适合的地点建立自然保护区。
Q4:同Q3,但是在亚太地区做迁移,给出技术性报告。
解决思路:
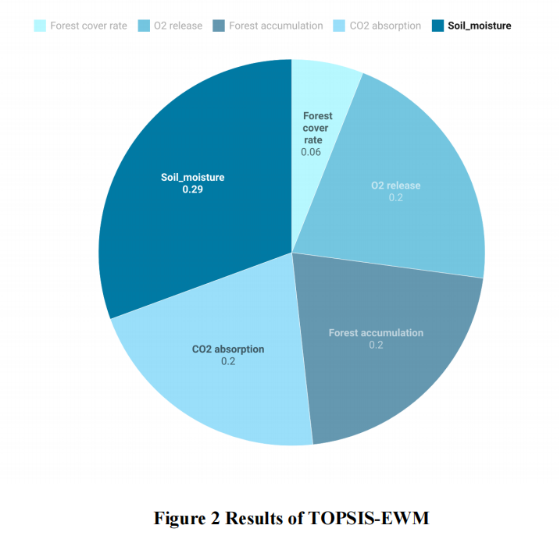
我们先对塞罕坝四十年来的几项数据做了层次分析,得出了大概的因子权重,“土壤含水量”是所有塞罕坝带来的环境变化中最重要的一个因子。然后基于此,我们进行了进一步的主成分分析与熵权法分析,确实获得了相同的结果。
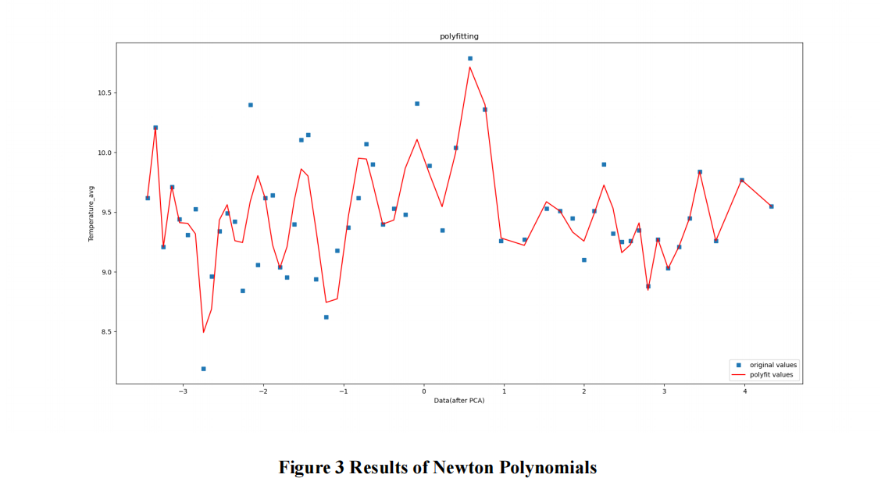
接着,我们以承德市平均气温作为塞罕坝周围环境的评估标准,用牛顿插值去拟合曲线观察气温变化,发现确实越来越趋于稳定,证明塞罕坝有起到一定的调理作用。
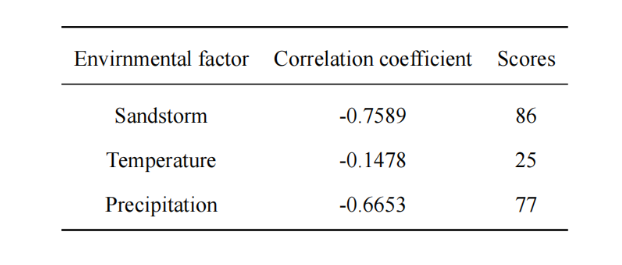
针对第二题,我们试图在塞罕坝的环境因子与北京市的沙尘天气数据之间建立联系。基于第一题的结果,我们选取含水量和二氧化碳吸收量作为代表,计算其与北京沙尘天气变化的关系系数,发现结果为0.8,证明了塞罕坝对北京市抵御风沙确实起到重要作用。
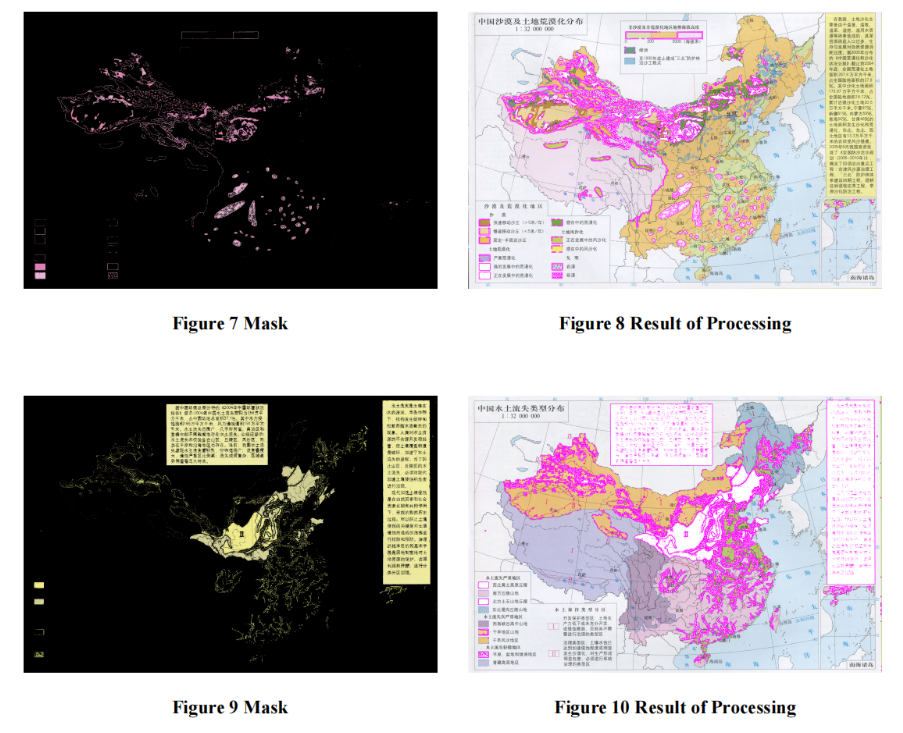
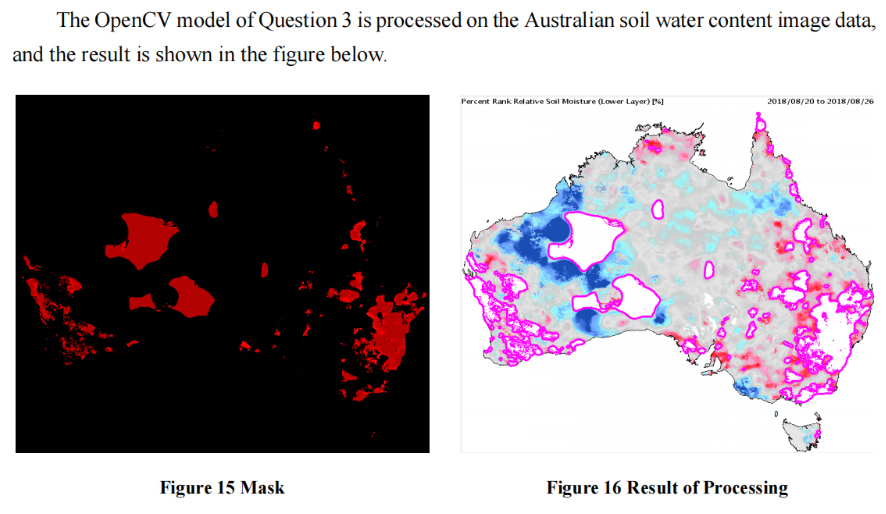
基于第一题的结果,对塞罕坝模式进行迁移的基础,是找到自然环境相似的地点。我们考虑了三项重要区位特征:水土流失、土地荒漠化、植被类型。逻辑是这样的:通过opencv对全国水土流失与土地荒漠化地图进行掩膜,提取和塞罕坝色块特征相同的区域,再比较它们与塞罕坝的植被特征(这里是基于我们找到的LiDAR数据)是否相似,来选取合适的地点。

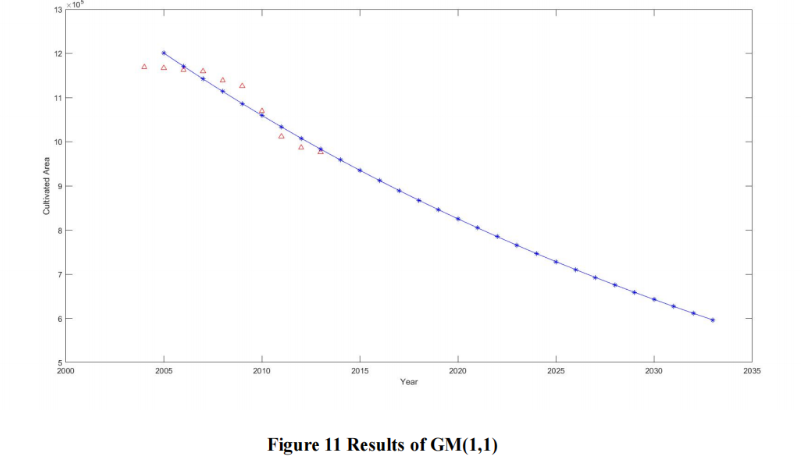
最后,选取榆林市作为例子进行自然保护区尺度评估。**借助榆林市政府公开的政府工作报告中的各类用地面积,**使用简单的灰度预测来预测近年来可用于建设自然保护区的区位面积。
问题四的解决思路和三相同,找相同区位特征,最后选取了澳大利亚的中部与西南部。
-
论文写作
有了solution,最后就是形成论文。实际上,摘要是最重要的部分,最好是想好一个问题的解决方案就进行记录。可以先通过谷歌机翻,然后再人工润色。
除了摘要,后面大体上的写作逻辑就是:问题描述、模型描述、算法原理、实验结果、分析结论。这样的逻辑写到最后,其实比想象中要顺利很多。强力推荐新手们就算以前没接触过,也要入门一下latex,写起来真的比word方便很多,也有很多现成的模板可以使用。
到了论文写作这一部分,其实也都是很细节的问题。比如图的脚注、表格的格式等等,很折磨人。因为前几天通了一次宵,把很多精力都留在了建模上,最后细扣论文的时候我简直像一具行尸走肉。
如果下次还参加的话,我给自己的建议是:**论文写作可以提前开始。**在建模的过程中就可以及时记录结果和素材,不要等最后再回过头来看自己的代码和结果。
赛后碎碎念
人生第一次真正意义上的通宵,献给了这次比赛。说实话,打完比赛之后那周,上早八的时候都能感受到心律不齐,还患上了“塞罕坝”PTSD,刚交完论文第二天,形策课上听到塞罕坝竟然不自觉地有点反胃…Anyway,当初是很难受,但是现在想想也都是很有趣的经历:
和cherish通宵前,我大放阙词:“我不可能睡着”。他嘲讽我说,一般这么说的人三点就睡了。事实上,我们最后都干到了天亮,然后同时昏倒在桌前。
和ruia、cherish在咖啡厅,吃了黄焖鸡、鸡公煲,大家闲聊些有的没的。
写论文的时候回看模型,突然发现跑的结果和我预想中完全相反,也和cherish的结果完全相反,吓得我一头冷汗,结果一看是数据集给错了。
ruia说到可以用土地荒漠化地图这种来做分析的时候,大家都很高兴,因为把所有题目都串起来了,所以我在“完善模型”那里表了红色。
正赛第一天遇到zngg,我不紧不慢的拿着圣代去实验室,他说:“你怎么这么悠闲!”可他不知道,我当时也慌的一批。
想找我们的建模课老师当指导老师,结果直到比赛结束我们才联系上他。
最后一天晚上,交作品前,我突然发现论文脚注标错了,是cherish的部分,赶紧看看他睡了没,结果真睡了,笑死,差点去他宿舍爆破他。
总之,很有趣,很有收获。


