Bert学习记录
写在前面:本人刚刚入门NLP,希望通过记录博客来巩固自己的知识,增进对知识的理解。
在之前的博客,我们进行了CRF的原理探寻以及借助CRF工具包实现各类序列标注任务,如中文分词、NER、拼音输入法等等。现在,让我们再上一个台阶,从统计自然语言模型到神经网络自然语言模型。由于最近在进行阅读理解(machine reading comprehension)的学习,因此选择bert这一微调模型的经典之作进行学习记录。现有的Bert可参考的博文也很多,我以个人的视角进行了精华提取,希望能对读者有所帮助。
Bert论文地址:https://arxiv.org/abs/1810.04805
Bert是什么?
Bert,全称为:Bidirectional Encoder Representations from Transformers,即双向性Transformer编码器。从它的名字我们可以得知,Bert的要点是:双向性+Transformer Encoder。接下来,我会围绕这两个要点,分别谈谈我自己的学习心得与看法,仅供参考,希望对你有帮助。
Bert解决了什么问题?
先说结论:Bert为NLP任务提供了泛化性强、效果显著的预训练模型。
什么是预训练?为什么这么重要?
在CV(图像)领域,有许多预训练模型和对应的预训练权重文件提供给公众使用。这些模型往往是在很大的数据集上(如ImageNet)已经进行了很彻底的训练,我们需要的时候直接对模型进行微调即可。
预训练与微调的关系就好比说,我现在有一个神经网络,它有50层深。开始的时候,我给它的数据集是各种品牌汽车的图片,里面有保时捷、宝马等等并且我也做好了数据集的标注,希望训练出一个能根据车辆图片识别出汽车品牌的神经网络。
训练完成,验证集上也获得了不错的效果后,我被告知:不需要一个能识别品牌的模型,只需要一个能识别出车型的模型,比如轿车、SUV、房车等等,但是这个任务的数据集又很小。那该怎么办呢?推翻重来?重新训练?其实不需要。你可以把你开始时训练的模型当作预训练模型,在上面根据你新的数据集进行微调。这样为什么有效呢?
答案是,神经网络模型的特点决定的这一切有效。在残差引入卷积网络之后,经典的卷积网络都走向窄而深的发展方向。在较浅的隐藏层,网络会学到初级的一些特征,比如车的轮廓、大体形状。再深一些的隐藏层,网络会学到更接近任务需求的特征,比如车的流形、车头的长相。对于我们目前遇到的新任务,其实浅层的网络参数不需要再重新学习了,因为车的轮廓和形状对我们很有用,我们直接冻结住这些参数。但是高层一些的特征或许不那么重要,我们可以对高层网络参数进行微调,比如直接重新训练softmax层,或者是重新训练没被冻结的隐藏层等等。
到这里,你应该明白了为什么预训练模型重要:因为实际生活中的任务很多样,为每个任务重新训练模型成本很高,也不见得有好的效果。
那NLP为什么到Bert之前,都没有这样的一种体系?
个人认为,这是因为在NLP领域,Bert出现之前,还尚未有很明确的知识告诉人们,越深的神经网络对自然语言处理也同样越有效,而且NLP的任务比CV复杂许多,图像说到底就是像素点,但是语言任务有处理词的、处理句子的、处理文章的,最小单位都不大相同,不同语种之间也有许多的语言性差异。但是预训练其实在NLP领域意义重大,因为许多语料数据要进行收集的话,可以很轻松地获得大体量的无标签数据集,但是要为各个任务打上标签,那将是很庞大乃至难以想象的工作量。一个好的预训练模型,可以大大提高NLP模型的落地应用转化率。
其实在Bert之前,也有许多工作在朝着这个方向努力。大体来说,主要是两种策略:
基于特征的预训练(feature-based)VS 基于微调的预训练(fine-tune)
前者的代表作是:ELMo
后者的代表作是:OpenAPI GPT
两者可以分别理解为:
feature-based:基于网络的调节,针对预训练得到的输出,还要设计相应的网络来应对不同的task。
fine-tune:基于参数的调节,针对预训练得到的网络进行网络参数的微调。
而Bert很明显,应该是属于后者这种接近CV的预训练策略。
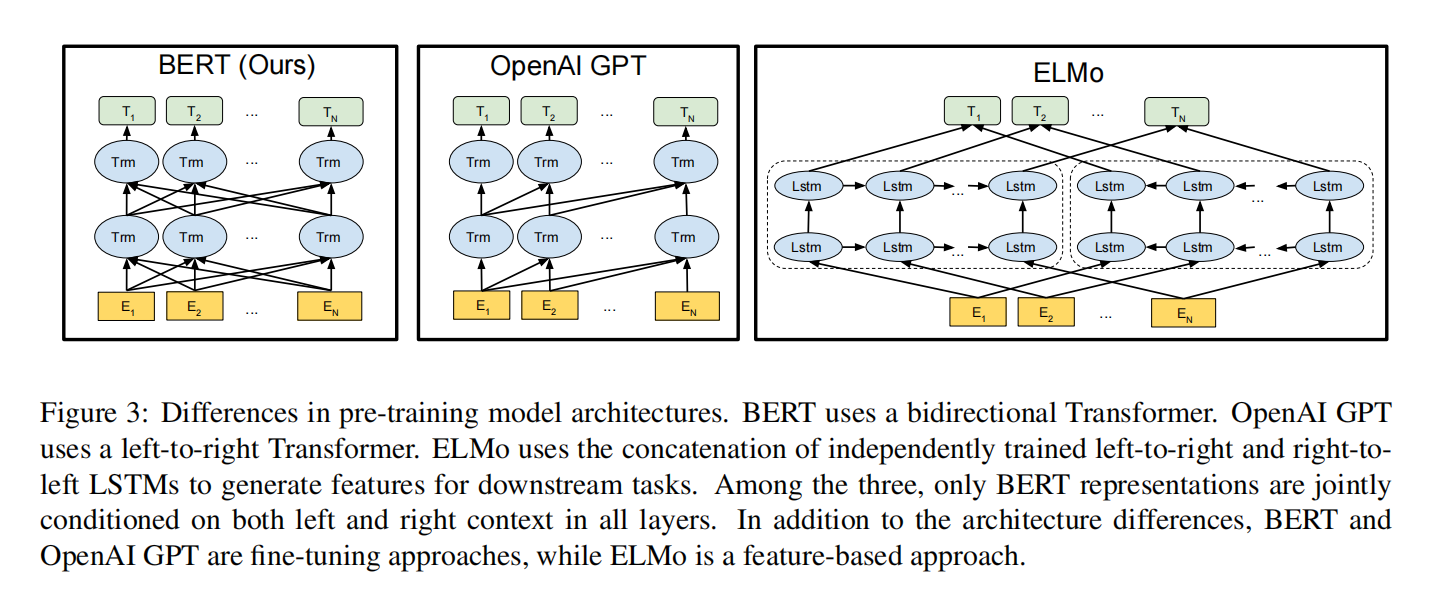
上图是Bert原文中,与GPT和ELMo做的对比。GPT和ELMo的内容不是本文重点,所以就根据上图进行简要的解释吧。
ELMo采用的是两个反向的LSTM网络进行训练,试图让两个网络的知识涵盖上下文信息。但实际上,这样直接的将一个从左到右的网络和从右到左的网络进行叠加,并不能在每一层都有效整合上下文信息。对于ELMo而言,主要需求是获取更多的语言特征,因此,ELMo的输出其实就是一个Word Embedding,对每个词进行了特征维度的扩展。
GPT采用的是transformer的解码器,是一个从左到右的模型。其实Bert和GPT的架构是类似的,都是transformer为基础,只不过Bert采用的是编码器,引入了双向性。GPT模型中,每一个词只能根据之前的词是什么来预测下一个词,不能结合下文信息进行预测。
在Bert之前的预训练模型与策略都有一些绕不开的局限性:上下文信息难以有效整合、句子层面的任务难以与字词层面的任务在一个预训练模型上相适应。
而Bert是集大成者,即保留了微调的思路,又引入了上下文信息,还兼顾了token-level与sentence-level的任务。
但是这种双向设计的transformer编码器,其实给Bert上了一把锁,具体是什么呢?我们继续往下看。
双向性(Bidirectional)的体现
在Bert中,双向性主要由掩膜语言模型、句子语序预测、自我注意力机制体现的。
掩膜语言模型–MLM
全称,masked language model。其实说白了,就是对输入的句子里面的token进行掩盖(加[mask]),然后让模型预测mask掉的词是什么。文中举的例子是这样的:

值得注意的是,并不是所有的token都会被mask掉,实际上是取输入中15%的token选中进行mask,并且被选中的token也只有80%的几率会被mask,还有10%是替换成别的词,以及10%的概率不mask。
这样设计的意义是什么呢?
个人认为,是通过加入了约束规则迫使模型主动地去学习上下文知识。如果不给予模型一个任务,很难控制模型的收敛走向。掩膜预测的任务能够帮助模型注重上下文信息,结合这些信息来推断某个token的意思。从这个角度也使得这个token的特征维度得到拓展,不止是token本身,还有上下文中与它相关的知识。
句子语序预测–NSP
全称,next sentence prediction。这个任务主要是对输入的句子对是否是顺承关系进行预测,句子对AB的中间以及结尾以[SEP]进行分隔,让模型判断B句子是否是A句子的下一句话。文中举的例子是这样的:

这个任务看起来很简单,也很好理解。后文的消融实验其实证明了它的作用并不显著,但是我认为NSP任务的设计,是为了将模型能更好地从token-level迁移到sentence-level。同时,我也认为MLM和NSP的设计都是为了弥补transformer本身缺乏序列信息的特点。
一点补充说明:RNN在序列信息的学习其实比起transformer要更加彻底一些,因为transformer会将序列里的每一个token都做自我注意力,导致你的token以任意排列顺序输入都不会有很大影响。所以transformer原本的论文加入了位置编码来缓解这一缺陷。
自我注意力机制会放在encoder的部分继续讲述。
Transformer Encoder
Bert的另一大要点,就是基于transformer的编码器作为网络架构。Bert的基本模型采用了12层编码器堆叠的架构:
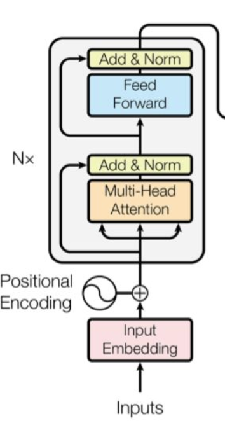
上图灰色的矩形内是编码器的基本架构,Bert基本上没有改变transformer的原本设计,直接引用了这个模块。关于编码器,我想,最重要的部分就是:Multi-Head Attention。
什么是Attention?
顾名思义,是注意力。你可以将两个向量之间的距离理解为注意力,离得越近,说明我越注意你;离得越远,说明我不需要怎么关心你。讲到向量,讲到距离,很自然地会联想到点乘,因为余弦可以在夹角层面上反应向量之间的距离,或者说,差异性。所以,transformer的原作者采用的就是这种思路来实现注意力:点乘注意力机制(Dot-Product Attention)。
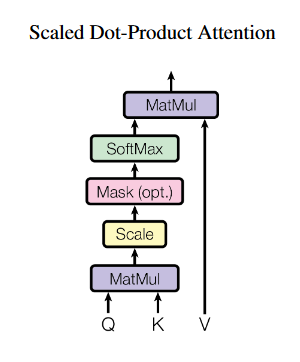
上图是点乘注意力机制的计算图。可以看到,基本思路是,将三个输入Q、K、V读入,其中Q与K进行矩阵相乘,进行尺度缩放之后,不掩膜的话就直接softmax得到注意力分数,再将这个分数与V相乘,得到最终结果。数学一点的表示是这样:
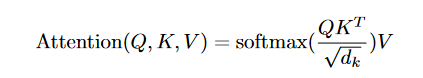
是不是很懵?没关系,我们一步步来。
首先让我们明确,什么是Q、K、V。Q是Query,意为查询;K是Key,意为键;V是Value,意为值。从编码器的结构也可以看出,Q、K、V的输入其实都是同一个东西,比如就是上一个隐藏层的输出。在上面的计算图中,我们实际上是通过Q和K的相乘来获得各个token之间的注意力。在这个过程中,矩阵Q的每一行和转置后的矩阵K的每一列都能做向量相乘,相当于是每一个token都和包括自己的其它token进行了计算。因此,可以将Q视作”查询“,代表我现在计算到了哪一个token;而K视作”键“,代表我现在针对我查询的token进行相对应的各个键的注意力计算。而V又是什么呢?实际上,Q与K相乘得到的结果,就代表了这段序列内部各个token与每个token之间的关系信息,乘以V实际上是将这种关系信息以权重的形式传给原本的输入,让它知道它本身的注意力信息是什么,自己内部的哪些部分联系更紧密、哪些部分关系不大。
那么,除以${\sqrt{d_{k}}}$又是什么意思呢?这里就是计算图上标题**”scaled“**的体现。原本我认为,除以这个数字单纯是防止对角线上的值过大(因为对角线是某个token和自己相乘,结果是1),把尺度缩小来减轻影响,但是经过学长点拨之后:

发现还有这样更加数学的解释,amazing!
初步理解attention之后,让我们继续看看什么是”multi-head“。
什么是”Multi-Head“?
多头,顾名思义,是在注意力机制的基础之上,多加了好多个”头“。可以简单理解为将上面的计算过程提前分成了好几份分开计算:
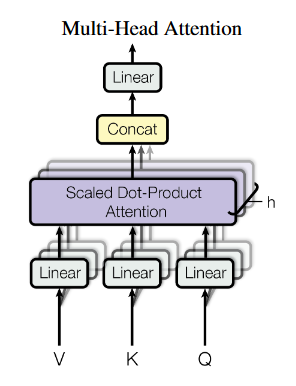
上图是多头注意力的模式图解,中间紫色框框内部就是我们刚刚讲到的点乘注意力模块。假设头的数目是h,那么其实就是将Q、K、V分成h份,各自进行点乘注意力。总共就是进行了h次。而且在输入处还能看到,每个头的Q、K、V都乘了一个矩阵(linear)进行映射。数学一点的表示是这样:

可以看到,多头做的事情其实就是将各个attention的结果拼接一下,再乘以一个输出矩阵融合信息。这里值得一提的是:为什么要乘以矩阵呢?其实,主要是因为Bert的训练资料比较丰富,可以拥有更多的可学习空间。如果不乘这个矩阵的话,其实分为多个头和不分多头直接点乘attention的结果没有什么区别。引入这几个矩阵之后,能提供更多的变化空间,让模型尽可能学到attention的多种模式。
在transformer原作的论文中也提到,这样的方式其实不会对计算量有更大要求,和一次计算完没什么区别。
了解完注意力机制后,让我们来看看Bert的整体结构。
Bert基本结构–预训练
Bert的三层嵌入
Bert的结构中,对于输入的token进行了三层嵌入(embedding):
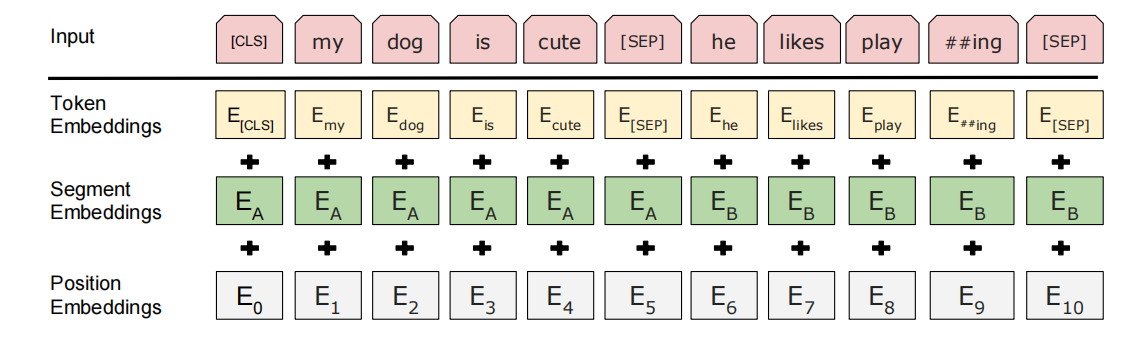
-
首先是Token Embedding:
这个步骤其实很简单,只是把输入的token乘以一个嵌入矩阵提升维度,为后续嵌入做准备。
**值得一提的是:**输入的token其实是经过了WordPiece的词根词缀字典查找获得的,所以会看到诸如”##ing“这样的形式,表示它不是一个完整的单词。WordPiece的字典大概是3w字量级。
还有一点是输入的开头,有个[CLS]token,表示输入的开始。每一层编码器的开头都含有这个[CLS],可以理解为整个block的一个代表,包括最后做分类任务的话,也是以[CLS]作为整个模型的信息融合结果的代表,进行分类。
-
接下来,是Segment Embedding:
这个嵌入部分是与NSP配合使用的,由于需要判断句子对是否有顺承关系,就要先对它们事先进行标记。以”A“代表第一句话,”B“代表第二句话。所以它的嵌入维度是:2*768。(图中小细节:第一个[SEP]属于A,第二个[SEP]属于B。)
-
最后,是Position Embedding:
Bert当中的位置编码与transformer中的实现不同,transformer原本工作中的位置编码是通过公式计算得到的:
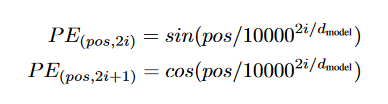
而Bert不同,Bert可学习参数足够多,也需要足够的空间来充分学习语义特征,因此Bert当中的位置编码也是一个可学习的嵌入。我们事先给好各个token对应的位置id(不大于512),然后初始化一个512*768大小的嵌入。
或许你会奇怪,为什么经常看到512、768、一对输入?
这是由于Bert预训练的初始设置决定的。一开始google预训练的时候,就设置了输入是一句或者一对句子,最长长度不超过512,隐藏层大小是768。
直观一些,看看源码
这里使用的是huggingface的pytorch版本Bert,比起TF版本感觉更好看明白一些。详细的讲解可以参考文章:https://zhuanlan.zhihu.com/p/369012642
1 | class BertEmbeddings(nn.Module): |
基本上可以根据代码设计来对照Bert论文给的图片一步步推导。
值得注意的是:计算完三种嵌入并将他们相加之后,需要进行LayerNorm+Dropout。LayerNorm是transformer原本工作就使用的归一化trick,与BatchNorm不同,LN的方式是在单个样本的维度上做归一化,而BN是在整个batch中做全局归一化。LN对于NLP任务来说更加合理,因为输入的长短不一,BN的话会出现很多向量长度不同,要补零,影响全局归一化。
Bert如何微调
讲完了Bert预训练的几大要点,让我们来看看Bert是怎么进行微调以适应更多task的。
自然语言推理–NLI
自然语言推理任务简单来说,就是根据句子对,来推理它们之间的关系,可以视作句子对的分类问题。Bert论文中给出的示意图如下:
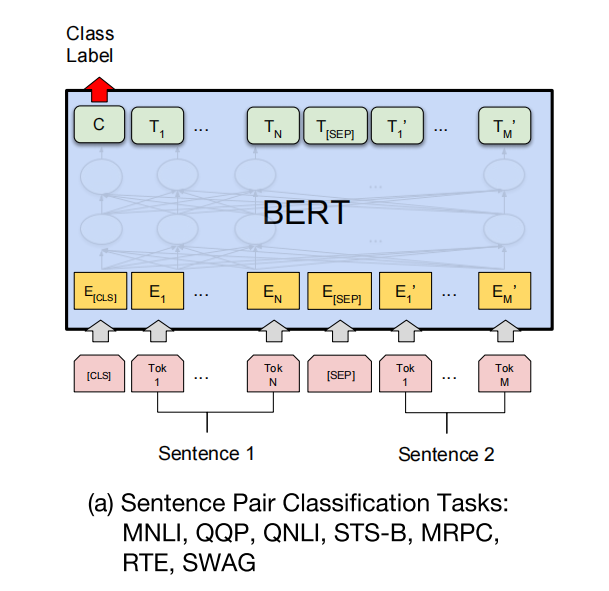
其实NLI任务本身就很贴合Bert的设计,与NSP任务也很接近。[CLS]这个class token也正好可以作为分类任务的输出。微调时只需要在[CLS]的输出上面加上一层或几层线性分类器,训练分类器即可。
单句分类任务–文本分类、情感分析
与NLI不同,这里的情况是输入不分为上下两部分,但任务依旧是分类任务。示意图:
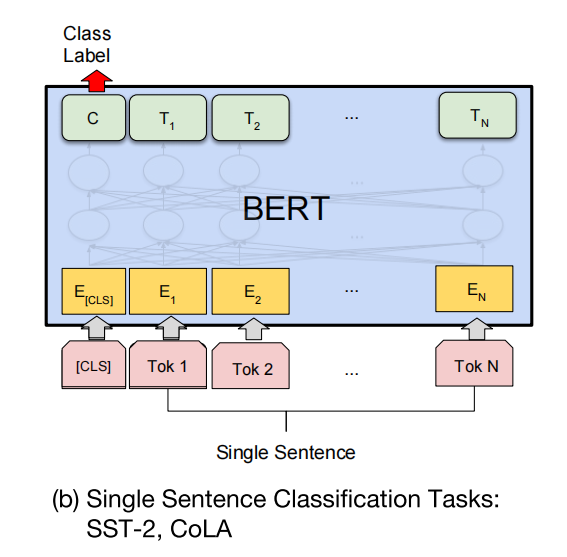
思路与NLI相同,也是在[CLS]上加线性分类器。
阅读理解任务–MRC
阅读理解,machine reading comprehension。阅读理解的任务广度很大,这里主要以QA举例子。也就是我输入一个问题加一篇文章,你要在文章中找到一个部分作为答案。示意图:
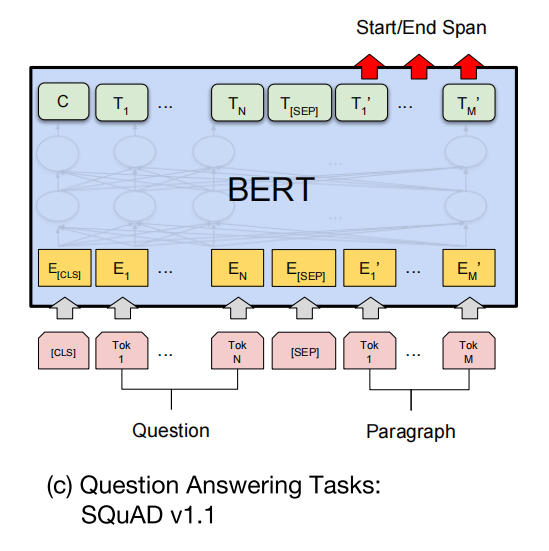
那我们是如何利用Bert做QA的呢?其实答案很粗暴,就是文章中对于每个token,分别预测它们作为答案开头和结尾的概率有多高。所以,微调的时候,会对每一个token分别学习两个向量:一个判断它是否作为开头token,一个判断它是否作为结尾token。再加上softmax获得各个token作为开头或者结尾的可能性,取开头中最大概率的和结尾中最大概率的,并将中间内容输出。
注意,这里就已经是token-level了。因为你可以看到,我们是对最后一层的所有属于文章的token进行处理,不再只是拿[CLS]作为代表。
序列标注问题–NER
序列标注问题就是很典型的token-level的问题,判断每一个token的标签。示意图:
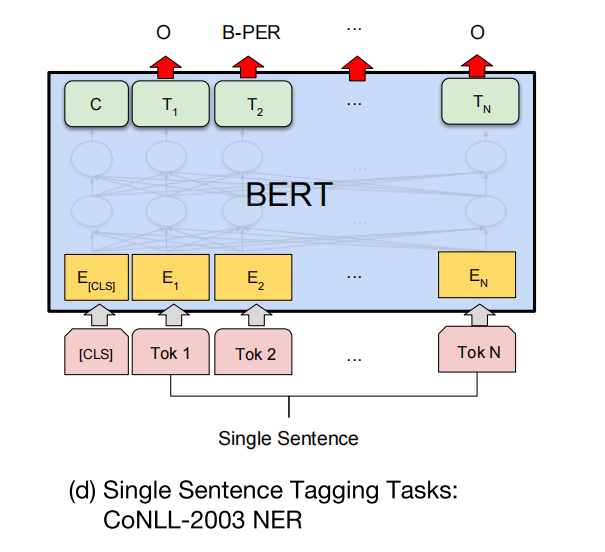
这里其实也很好理解,和QA一样是对每个token的输出做处理。但是不一样的地方在于,QA需要两次计算,算作为开头和结尾的概率。但是NER的话,只用在每个token上加一个类别的分类器来微调即可。
值得注意的是:其实这种NER方法依然限制在序列标注本身领域之内,只能对一串句子获得一组标签。但实际上我们知道,像:
”中国传媒大学“里面,”中国传媒大学“可以视作大学这个命名实体,但是”中国“也是国家层面的命名实体。这种交叠的(nested)命名实体问题不能用传统思路解决。香浓科技的这篇论文提供了一个新思路:用MRC对NER问题重新建模,取得了不错的效果。这也会是我接下来的学习方向,后续会更进这篇文章与我自己的想法。
所以,Bert到底学到了什么
看到这里,希望你对Bert是什么已经有了一定的了解。那么,让我们回到梦开始的地方,预训练。
上面说,CV中预训练可行的原因是,神经网络窄而深,并且不同的层级有学习到由浅到深不同的特征,这使得微调效果卓著。
那么Bert做到了吗?Bert各个层是否也学习了由浅到深不同层级的语义信息呢?
怀着这个问题,我看到了这篇文章:What does BERT learn about the structure of language?文章用很多分析手段从多角度研究了这个问题,这里我简要的记录一下。
短句句法特征

这张图片,原文的意思是大概是说,他们采用了对LSTM相同的研究手段来研究Bert对于短语级别的结构信息的捕捉情况。可以看出,Bert的前两层色块之间有明显的区分,说明Bert能捕捉到短语级别的特征信息,但是这些信息在高层(最后两层)消失了,说明低级特征确实没有表现在高层之中。
三级任务分析
在这一模块,作者研究了Bert在三大方面信息获取的表现:
-
表层信息–Surface
-
句法信息–Syntactic
-
语义信息–Semantic
结果如下:
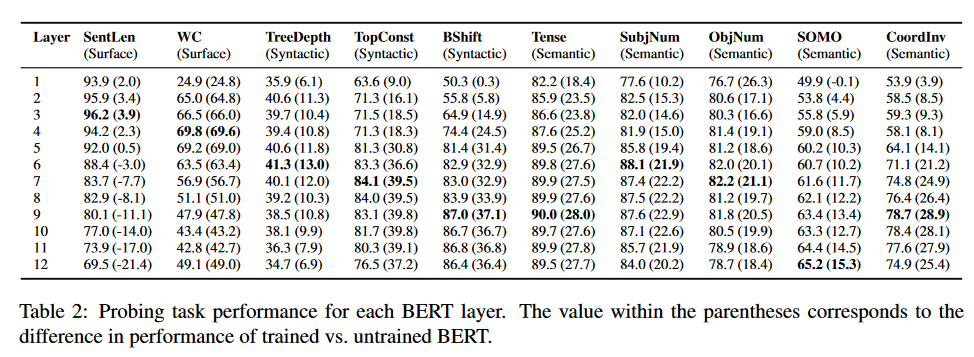
(括号里的内容是和没训练过直接随机初始化的Bert表现的分差)
可以看到,Bert的各个层确实在由浅入深地学习语义信息。
主谓一致
这个任务很有意思,个人理解是,在一句话中的主语和动词之间插入更多的名词进行噪声干扰,让模型预测动词的编号是多少。实验结果如下:
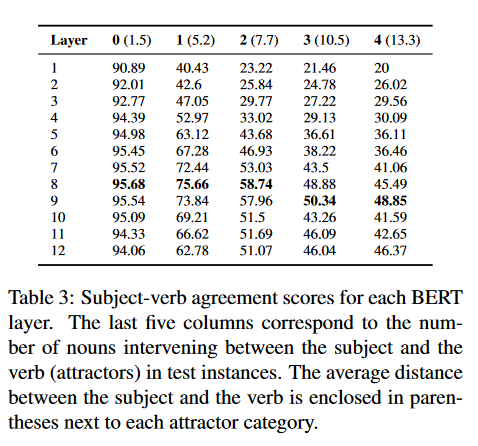
可以看出,对于中层的句法任务,插入的干扰越多,Bert越依赖更深层的网络来解决这个问题,也验证了Bert的网络越深或许在更加复杂的任务上会具有更强的表现。
注意力机制学到了什么?
作者通过Tensor Product Decomposition Networks(TPDN)来研究注意力机制的结构,得到了下图的依赖树:
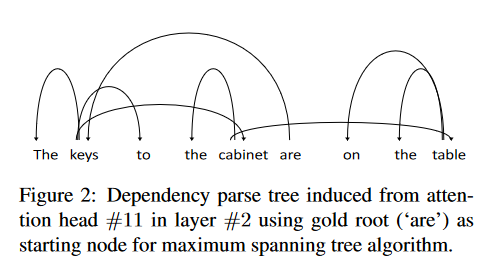
可以看出,注意力机制衍生的依赖树证明了Bert学习到了一些语法信息,这些依赖基本上与英语语法相吻合。
总结
贡献
个人认为Bert最大的贡献莫过于提供了一个可以被广泛应用的预训练模型,极大地推动了NLP领域的落地与应用。而且,Bert还可以迁移到多个语种上进行应用,不只局限于英语。
局限
前面埋了一个小彩蛋,说Bert被上了一把锁,那么具体是什么呢?其实,Bert的预训练策略导致它天然的不适合做自然语言生成(NLG)任务。因为NLG强调的是,我要根据当前的token和上文所有的一切来预测下一个token是什么,这是单向。而Bert的是双向的,它会自然地去结合上下文信息,这就导致它不适合NLG任务,或者机器翻译任务也不合适,因为它并没有使用transformer的解码器部分。像GPT采用单向的解码器,就可以适应NLG任务。
还有一点,是关于mask。预训练的时候,输入是有12%(15%80%)带[mask]的。可是微调与inference的时候,输入是不带[mask]的,这会使得Bert不太适应,不知道怎么去处理,造成一些瓶颈。而且,WordPiece可能是对词根词缀做了mask,但是理论上应该要对整个词进行掩盖才对,这又衍生出了一个改进方向:Bert-WWM*(whole-word-masking)**。
总之,Bert是里程碑式的工作,也是要理解当下众多自然语言处理模型的基础。所以做了比较详细的记录,特此感谢俊毅哥还有KNLP组中其他的小伙伴们!!




