“CS+X”-关于“轮子”
“CS+X”-关于“轮子”
讲完了关于开发环境的一些细节,这一部分,我想讲讲“轮子”。
可能很多非计算机专业的同学,没听说过“轮子”这个说法。其实“轮子”指的就是封装好的工具包,不需要自己从零开始实现一些功能。关于“轮子”这一说法是怎么来的:https://youtu.be/AQsZsgJ30AE?t=886
下面我会去掉双引号,直奔主题。
*看待轮子
程序员界很多人都说:“不要重复造轮子”。对于我们的需求–将计算机与自身学科结合的角度出发,其实尽量少造轮子得好。但讲真,我个人的感受是这样的:当你想要从头实现某个轮子的时候,不知不觉的,你也会用上其他轮子。当你使用轮子的时候,其实你也是在开发自己的轮子。所以,有时候不需要太过纠结,不想花时间实现并且与主要开发内容无关的部分,找找轮子吧。
但很多时候,我们也要从优化的角度出发。举一个我课程实验的例子,当时我是做一个APP内搜索引擎。我的搜索引擎有一个很基础的模块:分词。说到分词,大部分人第一反应就是大名鼎鼎的jieba库。jieba很用户友好,调用也很方便。但当时我正好对NLP有兴趣,想自己做分词功能,于是我就把我实现的和jieba的进行了对比,自己实现的分词器本地运行比调用jieba快了十几倍。所以,还是离不开具体需求。在我们这个系列,其实这方面需求不高,对于只需要应用的功能,还是优先考虑已经成熟的工具包。
如何判断
那么,对于我们的毕设项目,或者入门的跨学科项目,如何判断哪些模块需要自己开发、哪些模块优先找轮子呢?本质上还是需求分析。
我认为可以这样想:
对于某功能或模块,首先可以考虑:
该功能/模块,是否为项目核心部分?如果是,现有解决方案是否成熟?
对毕设来说,核心部分如果涉及方法创新,那么一定是自己实现为好,因为需要进行二次开发的可能性大,从头实现更有利于进一步优化。
第二步可以考虑:
该功能/模块,实现难度大不大?如果我自己从头做,做得来吗?
如果不涉及核心部分,那么第二步就是考虑是否有必要自己做、能不能做得出来。这一点很现实,因为不是核心的部分,自己实现如果耽搁了进度那是得不偿失的事情。
接着,也是非常重要的一步:
该功能/模块,目前已有轮子做的怎么样,成不成熟?
有一些功能,其实很多人都实现过,你会找到很多轮子;也有可能这个功能做的人很少,找到的轮子都质量不高。那么,就需要进一步了解这些实现过的工具,哪些更符合当下的需求。
具体举一个例子:
假如我从未做过ML/DL,且毕设的需求是改进手写体识别算法,我看到有人在预处理部分,比如边缘检测使用了Canny算子,我需要自己实现它吗?
一步步考虑。
首先,在我们的任务里,手写体识别是核心功能与模块,边缘检测这一部分不算最核心的部分,也大概率不需要我自己进行二次开发与优化,我只需要这个功能。
接着,这个功能实现起来麻烦吗?我以前从未接触过计算机视觉,更别提算子了!
最后,找一找关于Canny算子的轮子成熟吗?
opencv内置了!opencv是很正规完善的库,真香!
大概就是这么一个过程,当然,也可能在使用后发现不好用,选择新的轮子或者自己从头做都是可以的,一切围绕需求出发。
常用的一些库
面向ML/DL、数据分析等等,有一些库可能非常常用,也非常好用。
Numpy、Pandas、Scipy不用说,数据分析必备。
Scikit-Learn非常适合仅仅需要应用常见的机器学习方法,不需要对方法模型进行二次改进的场景。
Matplotlib、Seaborn、Plotly是画图神器。
OpenCV是计算机视觉方面非常好用的工具包,图像处理等等都有包括。
Jieba、NTLK都是自然语言处理很好用的包,各种教程也很全。
Pytorch、TensorFlow是目前常用的深度学习框架,适合开发深度学习模型。
等等等等,库很多,这里只是举最最最最常见的。
轮子可以参考,项目呢?
讲了轮子,那项目本身,是否能找到参考呢?核心模块的实现,是否一定是从0到1呢?也并不是。
学习总是从模仿开始,更何况我们目前的目的是快速将计算机的部分融入到自身学科中。阅读需求相似的项目代码,理解一些框架是如何使用的、数据是如何流动的,自己的项目要怎么组织。
知之为知之,不知为不知。参考与照搬,保持着微妙的关系。接下来,我会分享一些关于github基本使用、入门如何阅读项目代码的小想法,作为参考。
Github
有条件的建议尽量上🪜,不然只能参考教程配置DNS啥的。
这里我只分享我平时怎么去根据需求搜索相关项目,所以关于github的一些其他基本功能,可以去查其他教程。
搜索的第一要义:英文。
尽量把自己需求的关键词摘出来进行搜索。比如手写体识别,那就是handwritten recognition等等作为关键词。我们先输入进去:
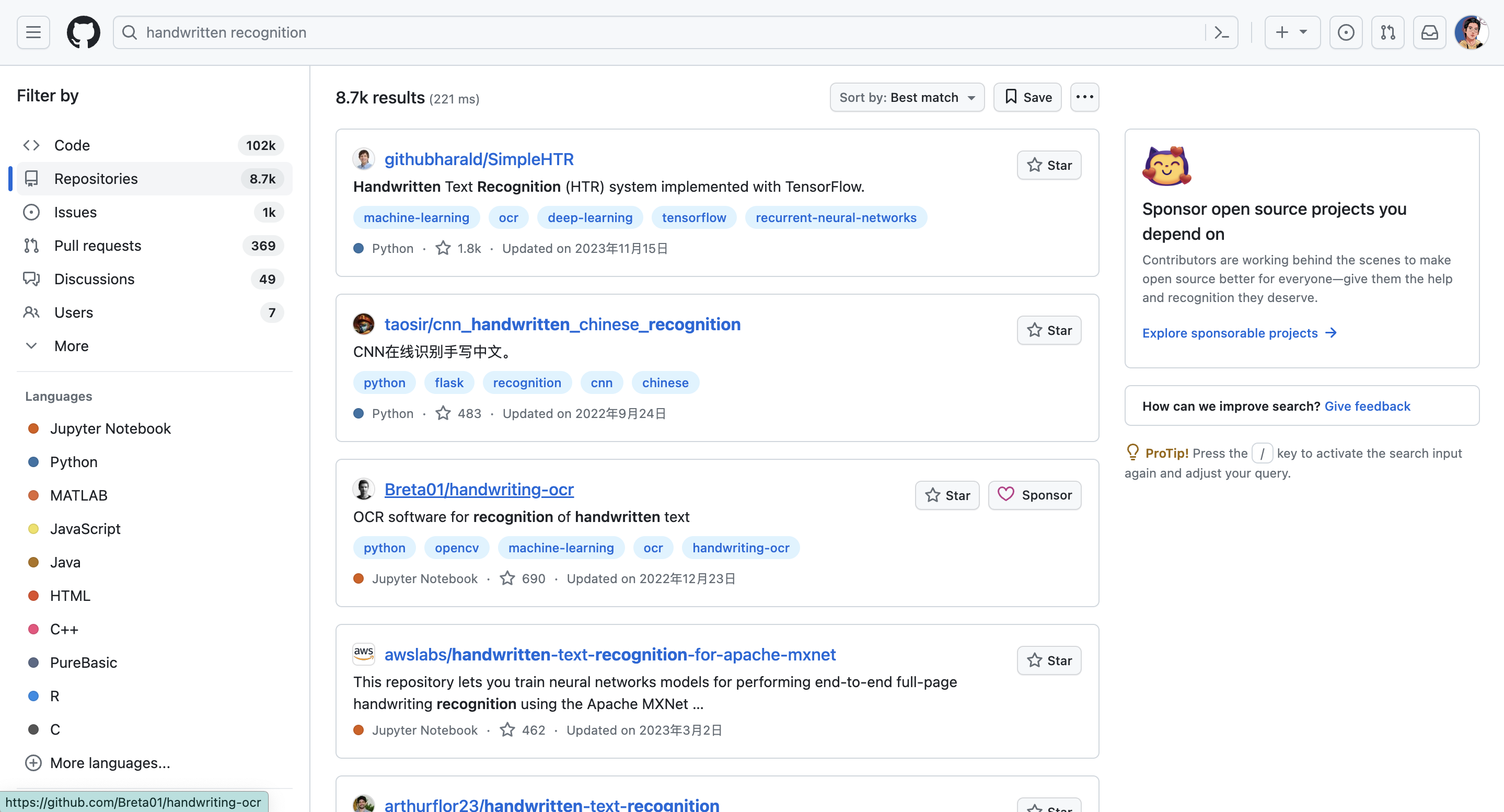
可以看到,已经有一些相关的项目存在了。左边可以过滤语言等等,详细的搜索语法可以参考github官方文档:https://docs.github.com/zh/search-github/getting-started-with-searching-on-github/about-searching-on-github (我们之前强调过,官方文档的重要性)
那么中文搜索会怎么样呢?
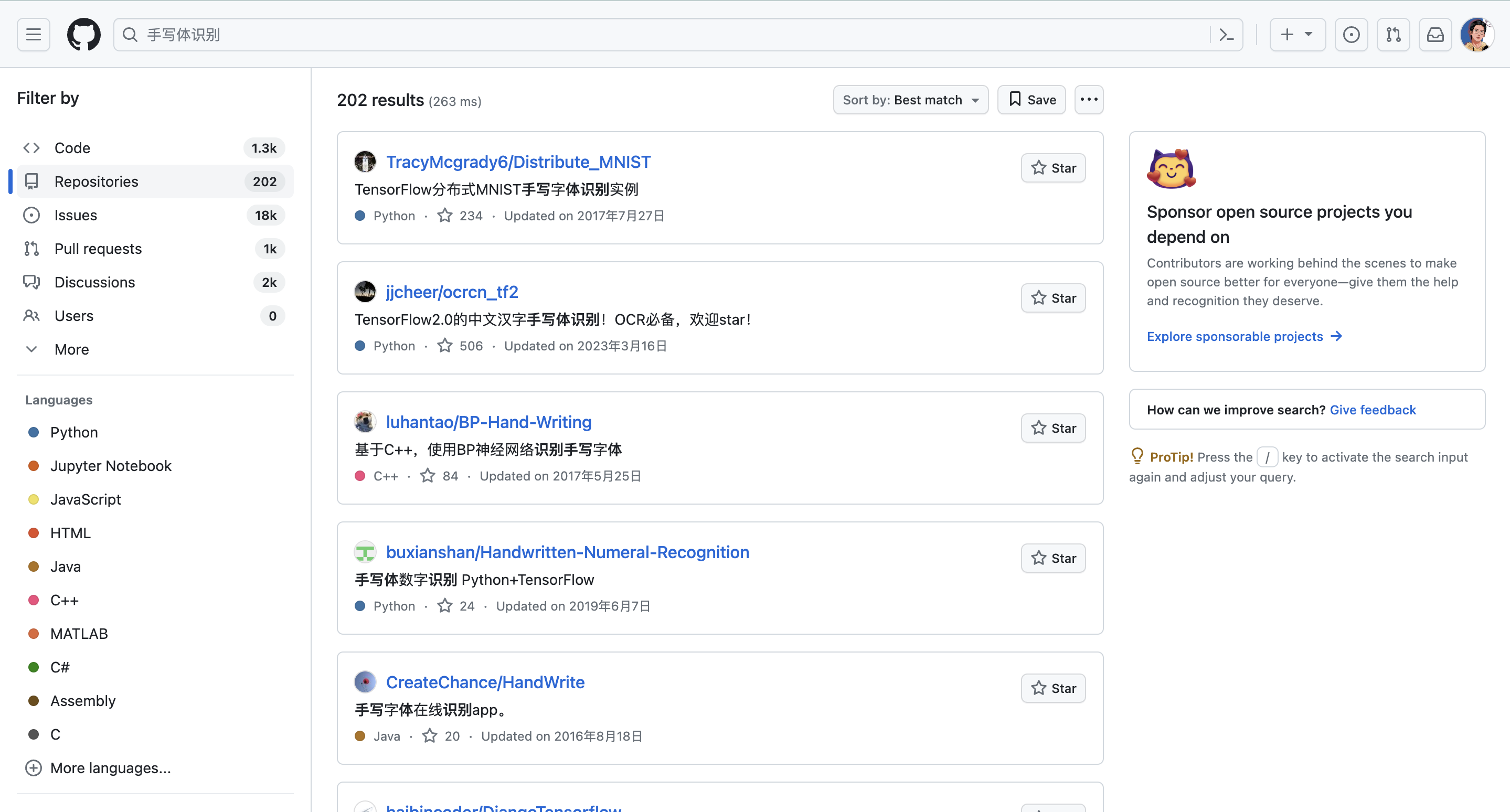
可以看到,搜出来的仓库只有202个,而英文搜出来有8.7千个。很多开发者习惯了用英文写文档,但中文搜索也可以反向排除一些情况:中文搜索出来的手写体识别,跟汉字识别的相关性可能更大(个人观点)
好了,搜出来这么多结果,该选择哪个入手呢?
一般来说,我会选择star相对高的库来看。star是这个:

除了star外,也要注意时间,不要太古早,ML与DL领域,方法是日新月异。
那么我现在点开第一个仓库看:
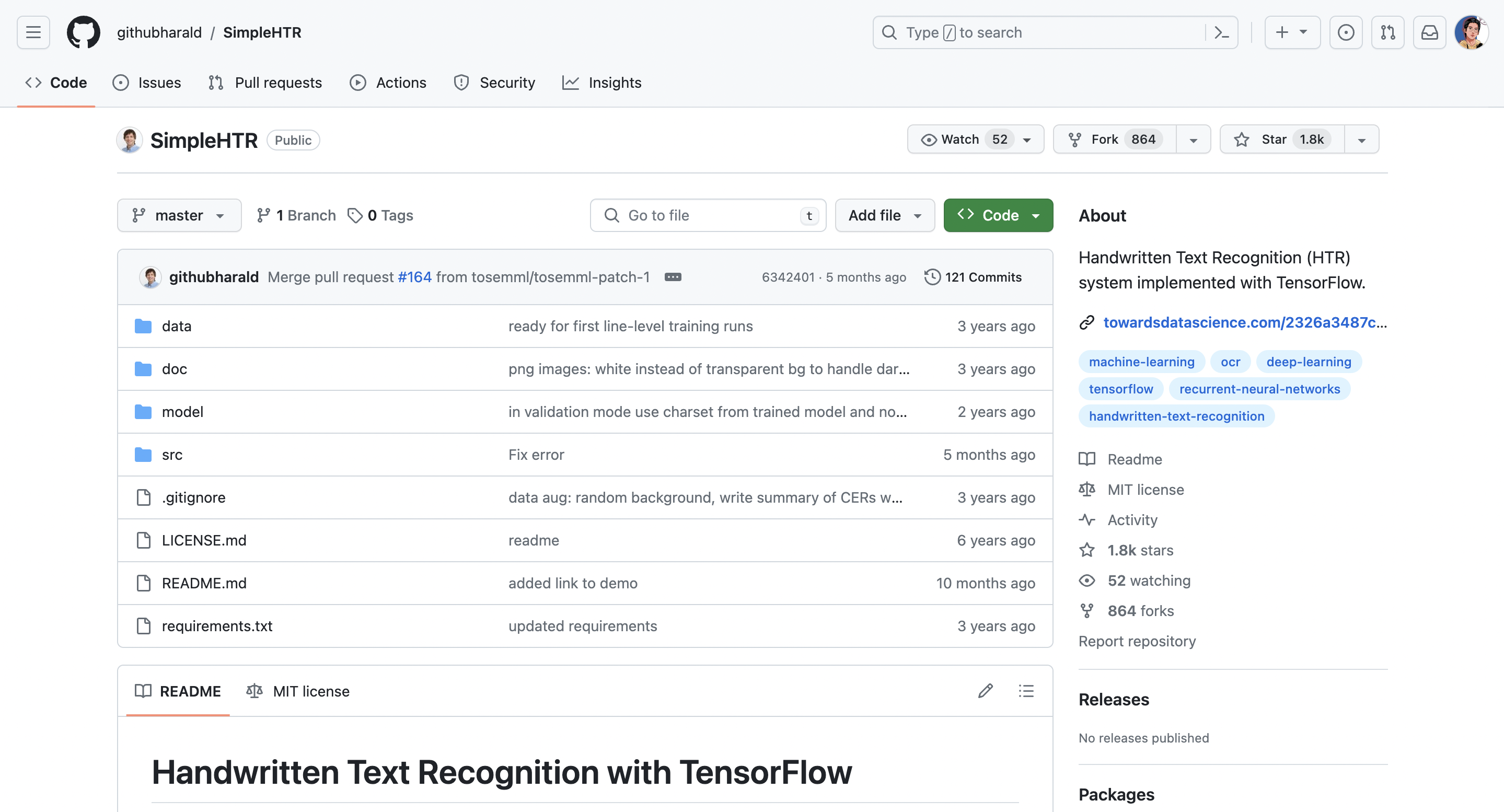
第一个值得注意的是:

license,许可证。这个部分我会放在这一篇最后介绍,知识产权的保护在开源社区中依然重要,但很多人可能并没有意识到这一点。
除了证书外,先看Readme:
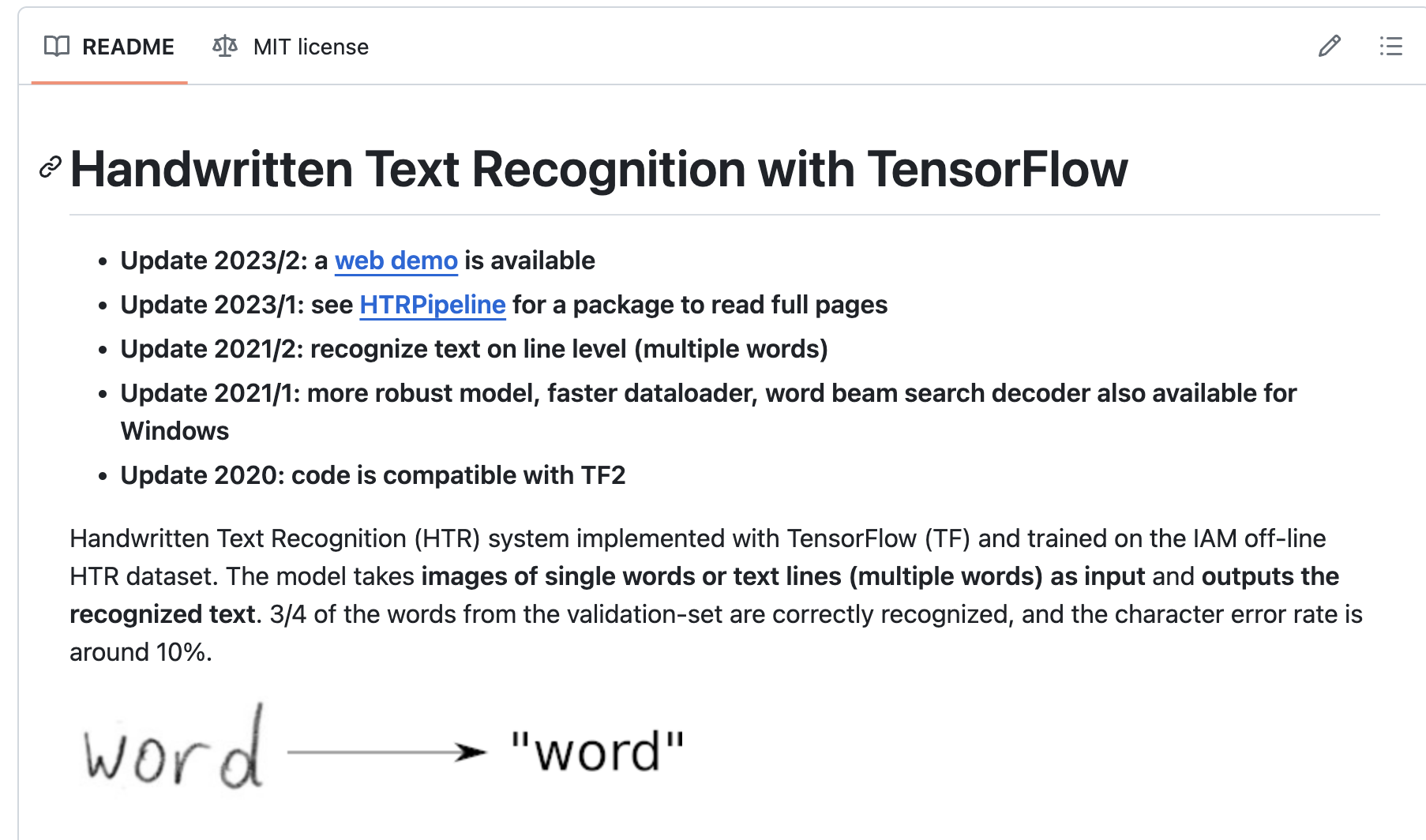
这种star特别多的仓库,往往都维护的比较好,文档比较齐全。大多数项目的Readme都写的很好,通过这个部分就能根据需求判断是否值得我们去参考学习这个项目了。
我们看到,需求与我们大体一致。那这个时候需要进一步在Readme里面关注:
如何安装与运行测试、使用的是什么方法。前者是方便我们在自己的数据样例上测试效果,后者是便于我们了解这个项目采用了什么解决方案,为我们自己的项目提供一些模型选型方向。
阅读一遍Readme,我们大概知道了这个项目能做到什么,怎么拿来测试呢?一般来说,我们会直接克隆这个项目的仓库到本地,但是这一步需要配置git工具https://git-scm.com/downloads。
我建议根据官方文档或者找教程,学习git工具的使用,尤其是最基本的克隆。但如果时间紧张,要尝试很多项目仓库,没学过git管理项目的话,直接点这里:
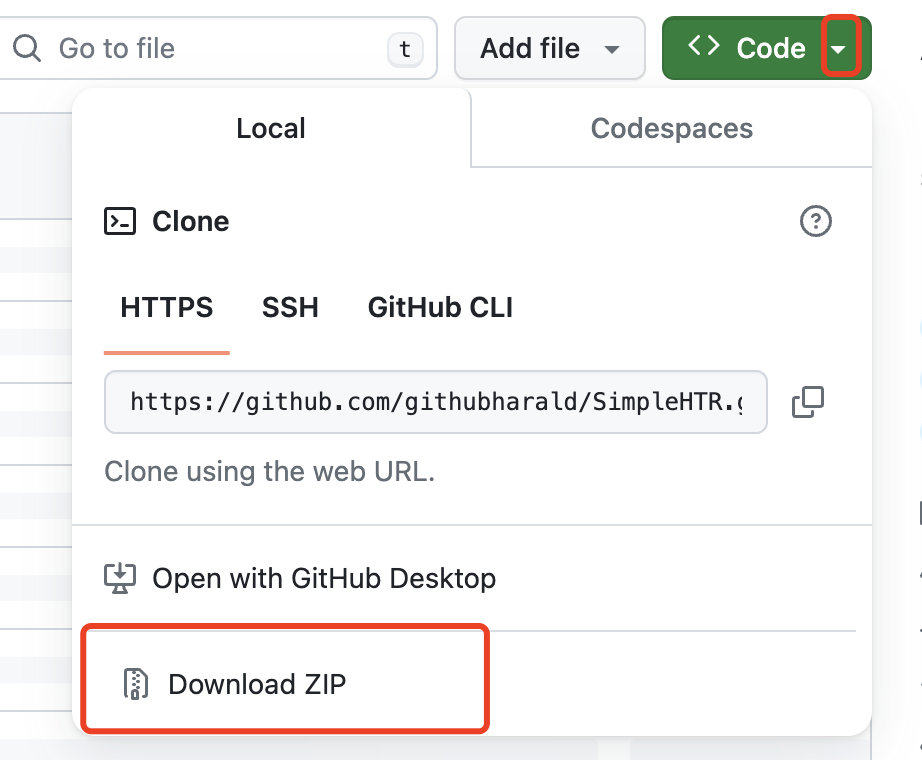
下载zip文件,解压。
解压出来之后,在IDE里面打开项目。再根据我们前面说过的,为每个项目创建一个虚拟环境,根据Readme里安装步骤进行配置。
这里要提一下的是,并不是每个项目都会友好地告诉你怎么配置他自己项目的环境,但绝大多数项目都会有requirements.txt这个文件,你先建好虚拟环境并且激活之后,pip install -r requirements.txt 一般就可以,后面运行项目的时候遇到问题再补充安装一些库即可。还有一种情况,就是没有requirements.txt,但是有environment.yml(也可能是别的名字,但是yml作为后缀)这种文件,这种可能是conda直接新建虚拟环境可以用到的配置文件,conda env create -f environment.yml 一般就可以。
有个我个人的小习惯:对github熟练一些之后,其实不一定要克隆到本地再去阅读代码,可以直接在项目的页面点击键盘上的”.”键,会召唤出github的在线IDE平台:

(加载中)

就出现了在线IDE,依然可以使用跳转等等,直接阅读代码。但我不建议在线上测试运行,可以先这样看看代码结构。
代码阅读
只针对真正的初学者,阅读ML、DL相关项目代码,我的一些小经验。
首先,一般来说Readme里面,关于运行测试的部分就相对于告诉了你项目的入口在哪里,比如这个项目就在这里:

看到这,我们就知道,哦,项目的入口在src目录下的main.py。点开一看:
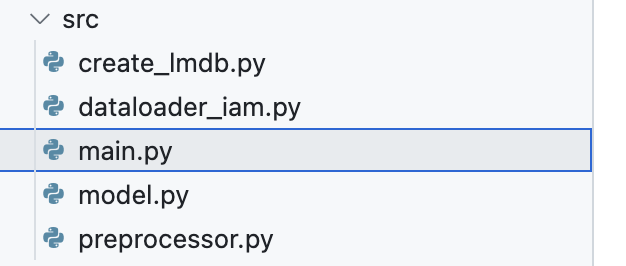
还真有嘿!
直接进去,找到整个代码文件运行起来的入口:主函数。(默认Python基本语法都了解了,函数定义的语法也了解了,有需要的话,也可以专门出一期在这个系列里,关于Python有哪些需要优先掌握的知识。)

也就是这里的main。
找到这里其实就轻松多了,Control+点击main(),转到main函数定义的部分:
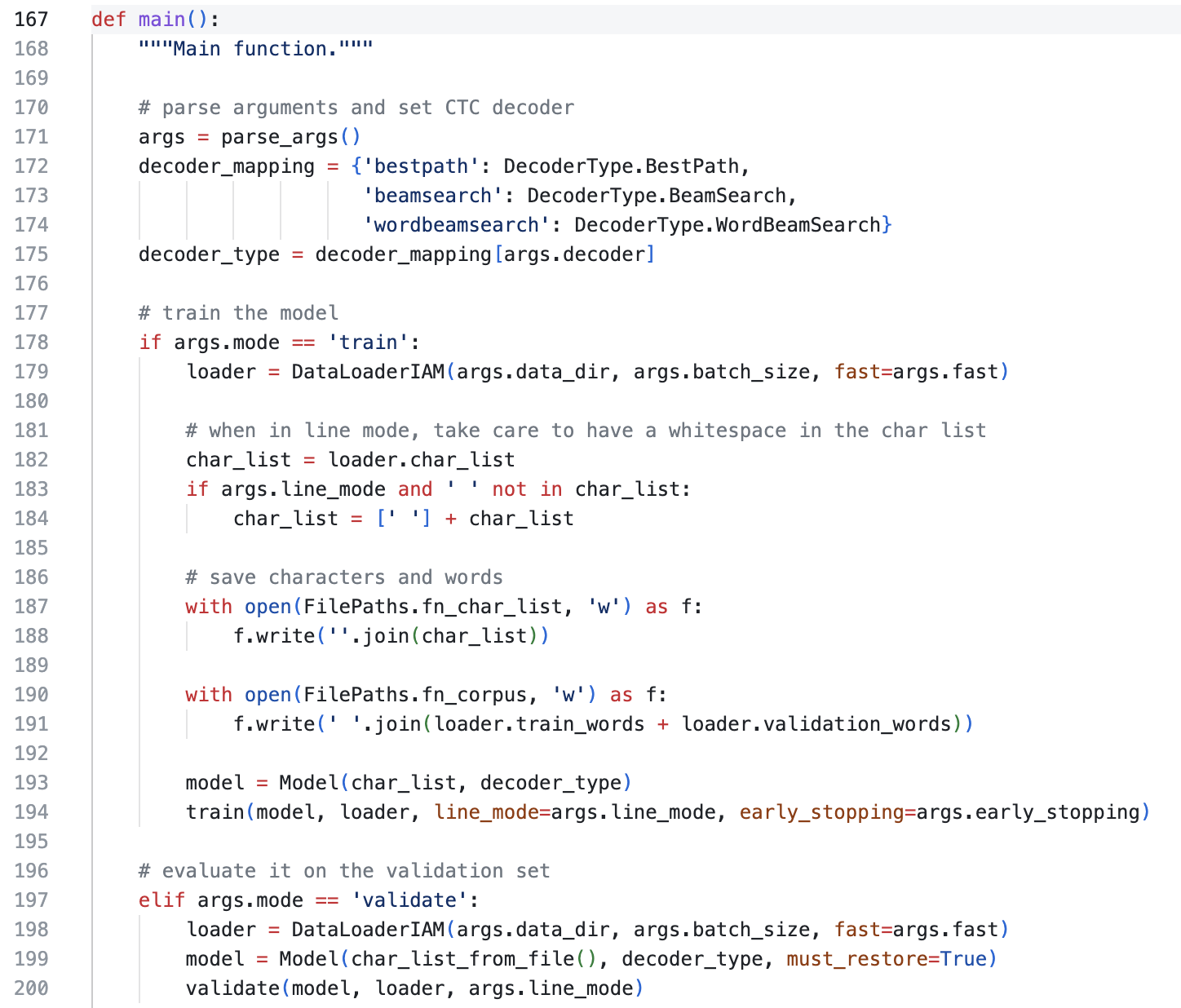
在这里,然后就一步一步阅读下去。对于ML与DL项目,我建议刚开始看的时候,不要太纠结细节,比如

这是什么东西呀,为什么要这样做呀什么的,先把整体逻辑看清楚。上面这一部分的整体逻辑就是:
先加载一些参数(arguments),然后判断一下是训练(train)还是验证(validate),训练的话就加载一下数据集(Dataloader),初始化模型(model),调用训练用到的函数。验证的话也是类似。这个流程大体先弄清楚,再一个一个点进去看,为什么这样写、这样做。
现在的大家是幸运的,有AI帮助读代码。不需要多SOTA的助手,不需要多漂亮的提示词,Chatgpt或者Bing在目前我们入门级别的项目就基本上足够了,能把一些代码的意义说的八九不离十。比如我这样问:

它答:

了解完基本逻辑,我们ML、DL项目最关心的几个内容就是:
数据加载、模型设计、训练。
对应到这里正好就是:


代码里有关数据加载、模型、训练的部分是最值得我们刚入手的时候学习的。因为这些是组成我们自己这样一个项目的最基本的模块。
一个个转进去看,看数据加载是怎么实现的,模型是怎么写的,训练是怎么组织设计的。
这些内容展开会很详细冗长,我主要分享一下思路:
数据加载部分,主要关注:对于这个项目的数据,它做了哪些预处理,我自己的项目的数据需不需要预处理?它怎么实现数据集里采样数据给训练和验证用?
模型部分,主要关注:用的是什么框架写的(Pytorch、TensorFlow等等)?模型的基本模块有哪些(一般在init里)?模型怎么堆砌这些模块?数据进来之后,是怎么在模型里面进行一步一步运算的?(这里就是我更喜欢Pytorch的原因,整个流程更加清晰。)
训练部分,主要关注:数据在哪里喂给模型的?损失函数是什么?超参数在哪里传进去的?如果我自己的模型要训练,是不是也要按照这个格式来写,对我有没有参考价值?
其实,我个人最喜欢的方式,就是先把项目运行起来,跑通之后,再在我没看懂的地方打上print,打印出结果看看是什么样的,来进一步理解。其实debug也可以,但我更喜欢打印。
Bugs
毫无疑问,第一次运行起来这些项目代码,绝对不可能顺顺利利。
我个人刚开始接触的时候,大抵遇到的bug可以这样分类:
- 安装问题,报错主要跟某个安装包有关,比如某某安装包没有某某函数,这种大概率是没装对版本,或者是装错包了。
- 框架问题,TensorFlow就经常因为版本对不齐而抽风。
- 自己的问题,数据没放好位置,或者运行的时候有哪些参数没设置好等等。
- 项目本身的问题,严格按照Readme里面的要求进行,使用了一样的数据,但报错或者结果不一致,可以去issue里查看有没有类似问题,或者是提出一个issue来提问(对于新手可能有点过了,因为可能是自己的问题,刚入门还是以搜索为主):
但Bug是无情的,每个哈姆雷特都有自己的Bug,善用搜索引擎,善于自我批评与自我革命。很多次我都以为是别人的问题,到头来全是我的问题。
知识产权
在Github上,找到了不错的项目或者轮子,希望能用到自己的项目里,需要注意什么?
举个例子,如果你使用了某个开源项目,并且做了修改,但是修改后的代码没有开源,那么有可能会违反许可证协议。所以一定要注意,虽然我们的项目可能并没有任何影响力,但是保护他人的知识产权,就是保护我们自己的开源环境。
是真的存在因为违反开源协议被告上法庭的事件,我们作为开源社区的一份子,权利和义务都要抓住。
可以参考:https://www.cnblogs.com/shenStudy/p/17744662.html 查看许可证的区别,里面提到的网站:https://choosealicense.com/ 非常实用。
小结
这一篇主要介绍了关于轮子的问题,与刚入门读项目的思路。讲的不全也不多,只是随想随录。
每次都是凌晨撰写,脑袋晕晕的,有任何问题请随意指正。


